Architecture of the carbon.txt validator
This page provides a high-level explanation of the carbon.txt validator and its architecture.
What is the carbon.txt validator
The carbon.txt validator is a command-line tool (CLI) as well as a deployable API. The main purpose of the validator is to read the content of carbon.txt files and validate them against a spec defined on http://carbontxt.org.
The code for the validator is open source, and can be found on GitHub. Further, more detailed, documentation can be found at https://carbon-txt-validator.readthedocs.io/en/latest/.
Carbon.txt validator architecture
How carbon.txt is designed
The following diagrams use the C4 model for describing software architecture to describe how the Carbon.txt validator is designed.
Context View
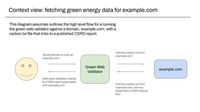
The context view demonstrate how we expect the validator to be used by end-users.
These might be people using the validator via the carbon.txt website, as command line tool, or in a data pipeline,
In all cases the key idea is that the validator is designed to run lookups against a given domain, to find the published sustainability data for later processing.
Containers

The validator is designed to work as a single deployable unit. This might be as a server providing an API, or as part of a batch job, running on a periodically on an existing host.
Components

The carbon.txt validator is split into a series of components, with clear divisions of responsibility
- Finders: Finders are responsible for accepting a domain or URI, and resolving it to the final URI where a carbon.txt file is accessible, for fetching and reading.
- Parsers: Parsers are responsible for parsing carbon.txt files, then making sure they valid and conform to the required data schema.
- Processors(s): Processors are responsible for parsing specific kinds of linked documents, and data, and returning a valid data structure.
We cover these in more detail below
Finders
A Finder is responsible for locating and fetching a files, either from remote sources or from local paths on the same machine. It's the only part of the system that makes outbound network requests. They are expected to make DNS lookups, and HTTPS requests, local path resolution, and they are responsible for handling related retry and failure handling logic.
They are responsible for sending along strings or datastructures to Parsers and Processors. When links to remote files exist in parsed carbon.txt files, the finders handle finding and fetching too.
The intention is to keep the logic for similar tasks related to finding and retrieving file in one place.
Parsers
Parsers in this context are primarily responsible for checking that a datastructure, or contents of a retrieved carbon.txt file meet the expected format and structure.
They don't make network requests. Where a carbon.txt file links to specific kinds of resources like CSRD reports, or external webpages, they delegate to the corresponding Processor for that kind of resource.
Parsers only work with strings of datastructures and are not responsible for any further IO.
Processors
Processors are responsible for extracting useable data out of disclosure documents linked in a carbon.txt file. They contain logic specific to a given kind of linked document, and different documents will have different processors.
So, for a CSRD report that is written to fit pre-agreed standards, like being written as an iXBRL document, and following reporting standard like the ESRS and we would have a CSRD processor that relies on software designed to parse and extract this kind of data, like the open source Arelle XBRL parsing library.
Classes

The In our CSRD Processor uses Arelle, an open source library for working with XBRL documents, to turn XBRL-formatted CSRD reports into datastructures that can be manipulated in Python, and that can be checked for the existence of specific data points.
The validation results are returned in API responses, or the output in CLI commands.
-

- Home
-
-
CO2.js
- Overview
- Installation
- Roadmap
- Overview
- Overview
- perByte
- perByteTrace
- perVisit
- perVisitTrace
- Overview
- Electricity Maps
- Average intensity
- Marginal intensity
- Getting started: In the browser
- Getting started: NodeJS
- Getting started: Impact Framework
- Check a domain for green hosting
- Customise website carbon calculations
- Get segment-level results
-
-
-
Greencheck API
-